
Mạng nơ-ron tích chập ( Convolutional Neural Network).
Phần 4: Mạng nơ-ron tích chập ( Convolutional Neural Network)
Làm cách nào người ta nhận diện được vật trong ảnh. Quá trình sẽ như thế này.
Truyền cái ảnh vào mạng nơ-ron tích chập, và nhận nhẫn trả ra. Mạng sẽ trả ra nhãn của vật trong hình.
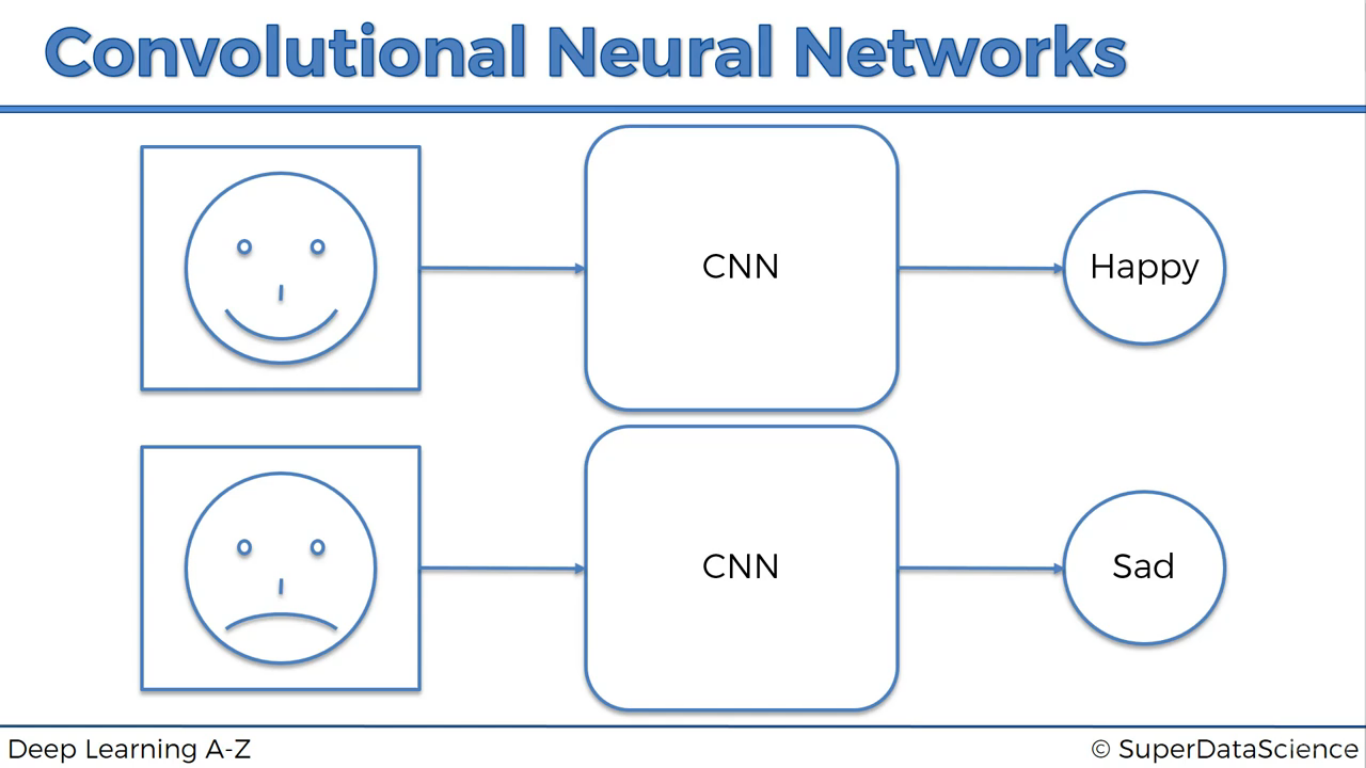
- Một bức ảnh được truyền vào như thế nào?
Một bức ảnh gồm rất nhiều điểm ảnh, mỗi điểm sẽ được chuyển thành 1 giá trị nguyên từ 0 đến 255, rồi truyền vào mạng. - Làm cách nào để chuyển 1 điểm ảnh thành số nguyên?
Nếu là ảnh đen trắng thì dễ rồi, càng đen thì số càng to, trắng là 0, đến đen nhất là 255. Còn ảnh màu thì như thế nào? Ảnh màu lưu dạng GRB(Green-Red-Blue: Xanh-Đỏ -Lam) nên sẽ có 3 số nguyên cho 3 màu Xanh, Đỏ, Lam.
Vậy là 1 hình ảnh sẽ có dạng như thế này.
Giờ nhìn vào cái CNN. CNN là gì?
Mạng nơ-ron tích chập (Convolutional Neural Network)
Mạng nơ-ron tích chập trông như thế này.
Input là cái ảnh đã được nói phía trên. Các phần sau của input sẽ được nói ở dưới đây.
CNN gồm 4 bước xử lí:
- Bước 1: Tích chập (Convolution)
- Bước 1b: Lớp ReLU
- Bước 2: Gộp vào (Pooling)
- Bước 3: Làm phẳng (Flattening)
- Bước 4: Mạng nơ-ron đầy đủ (Full Connection) ở phần 3
Bước 1: Tích chập (CONVOLUTION)
Tích chập của hàm f(t) và g(t) được định nghĩa như sau:
Đã thấy nó đơn giản chưa (\^o^). Nếu thấy nó đơn giản rồi thì bạn đếch về thế giới này. Hãy tắt ngay trình duyệt và trở về thế giới của bạn.
Nếu f(t) là việc bạn nhấn chân ga tăng tốc, g(t) là việc thằng bên cạnh đạp phanh giảm tốc thì tích chập (f*g)(t) là quảng đường của vận tốc do (bạn đạp ga tăng tốc nhân với thằng bên cạnh nhả phanh (ngược lại với đạp phanh)).
Nhưng cái ảnh của mình lại là các điểm rời rạc. Tích chập của hàm rời rạc lại dễ hiểu hiểu nhiều.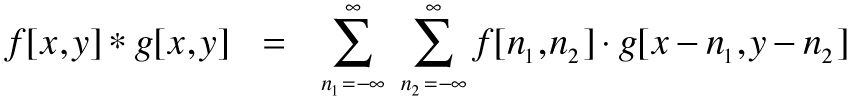
(Vẫn đếch hiểu gì.) Mình tìm được 1 trang giải thích khá dễ hiểu. Đầu tiên, ở cái 1D filter, chọn cái shift g(t)=1 tại t=-1,g(t)=0 tại t!=-1 , sẽ thấy kết quả của tích chập là dịch hàm f(t) 1 khoảng nhất định. Tùy thuộc vào hàm g(t) sẽ cho kết quả khác nhau, dịch trái phải, làm phẳng, … Với 1 cái ảnh 2 chiều dọc ngang như phần 2D. Cách tính tích chập như thế này.
Nhìn hình đã thấy nó đơn giản chưa (\^_^).
Với hình mặt cười ban đầu, và 1 cái filter ngẫu nhiên, kết quả là ntn.
Bước 1b: Lớp ReLU
Mỗi giá trị của Feature Map sẽ đi qua nơ-ron reLU để loại bỏ phần giá trị âm, làm mất tính tuyến tính giữa các điểm trong Map.
Map trước lớp RuLU trông như thế này. Có 1 khoảng chuyển giữa vùng sáng và vùng tối.
Sau khi qua lớp ReLU, khoảng chuyển này đã bị loại bỏ.
Bước 2: Gộp vào (Pooling)
Làm cách nào để CNN nhận rdiện đc đối tượng ở nhiều khía cạnh khác nhau?
Trong thực tế còn phức tạp hơn nhiều.
Việc gộp lại sẽ giúp giảm quyết vấn đề này.
Có 3 loại gộp:
- Gộp mean (Mean pooling)
- Gộp max (Max pooling)
- Gộp tổng (Sum pooling)
Chúng ta tập trung vào gộp max. Chúng ta gộp theo 4 ô 2x2 từ trên trái dịch dần sang phải, xuống dưới. Mỗi lần dịch 2 ô. Trong mỗi nhóm 4 ô, lấy giá trị lớn nhất làm kết quả của gộp.
Bước 1,1b và 2 thường được lặp lại nhiều lần tuỳ theo thiết kế CNN của tác giả.
Bước 3: Làm phẳng (Flattening)
Đơn giản là duỗi thẳng cái hình chữ nhật ra.
Vì có nhiều map nên sẽ như thế này
Bước 4: Mạng nơ-ron đầy đủ (Full Connection)

Nếu để phân loại chó và mèo thì nó sẽ trông như thế này:
Tổng kết lại như thế này

Nội dung chi tiết có thể xem tại đây