
Mạng nơ-ron nhân tạo ( Artificial Neural Networks)
Mình là đứa ngu toán, dốt lý, không biết gì về hóa, nên mình sẽ giải thích mọi thứ theo cách dễ hiểu, không liên quan đến toán.
Bài 2: Mạng nơ-ron nhân tạo ( Artificial Neural Networks)
Nơ-ron là cái gì
Nơ-ron là cái này.
Một tế bào nơ-ron gồm các sợi nhánh (Dendrite), thân (Cell body) và sợi trục (Axon). Tế bào nhận thông tin từ các sợi nhánh, xử lí thông tin và truyền ra ở sợi trục.
Nơ-ron nhân tạo mô phỏng lại hoạt động của nơ-ron thật.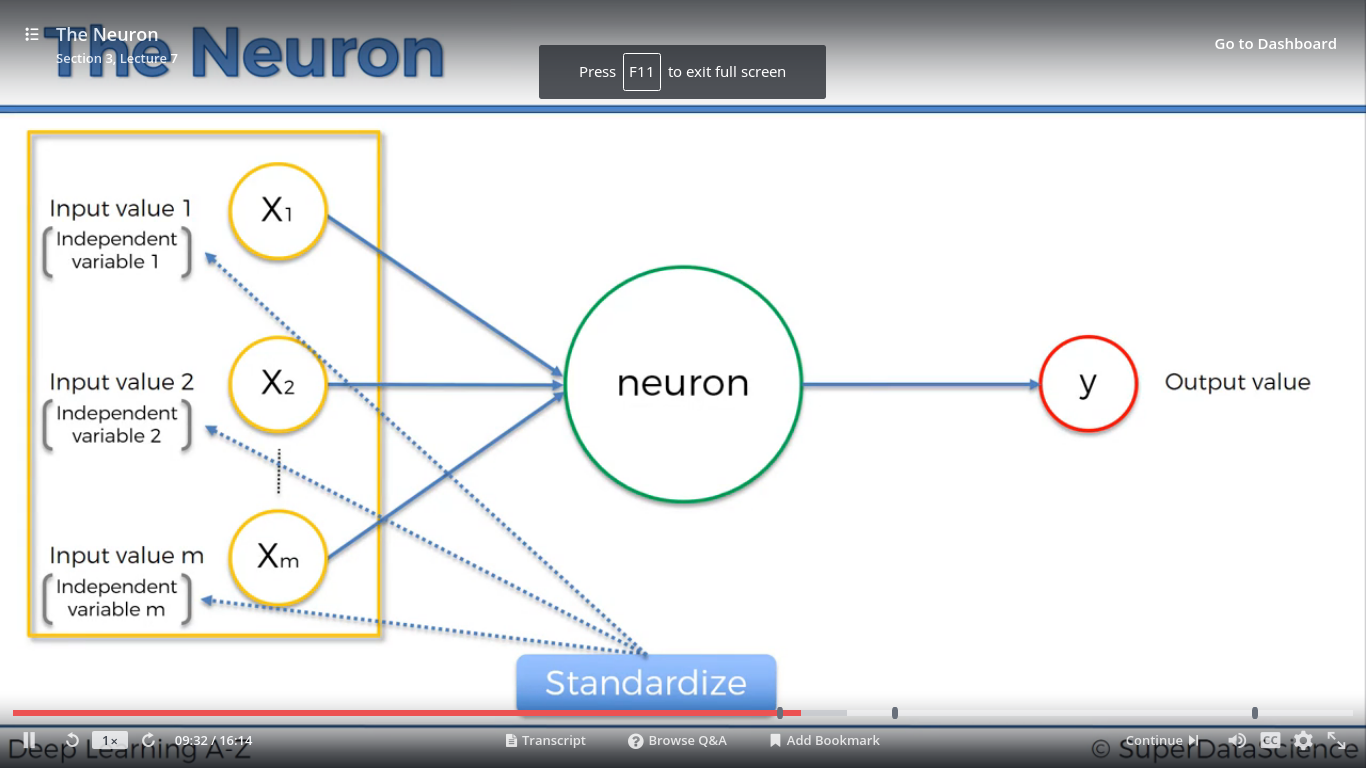
Đầu vào là giá trị các biến từ X1 đến Xm. Đầu ra là biến Y.
Ứng với mỗi biến X sẽ có 1 trọng số tương ứng W, từ W1 đến Wm. Các trọng số có thể thay đổi được giá trị.
Hoạt động của nơ-ron nhân tạo như sau:
Bước 1: Tổng giá trị đầu vào = Tổng của các biến Xn nhân với trọng số Wn của nó.
X= X1W1 + X2W2 +…+ Xm*Wm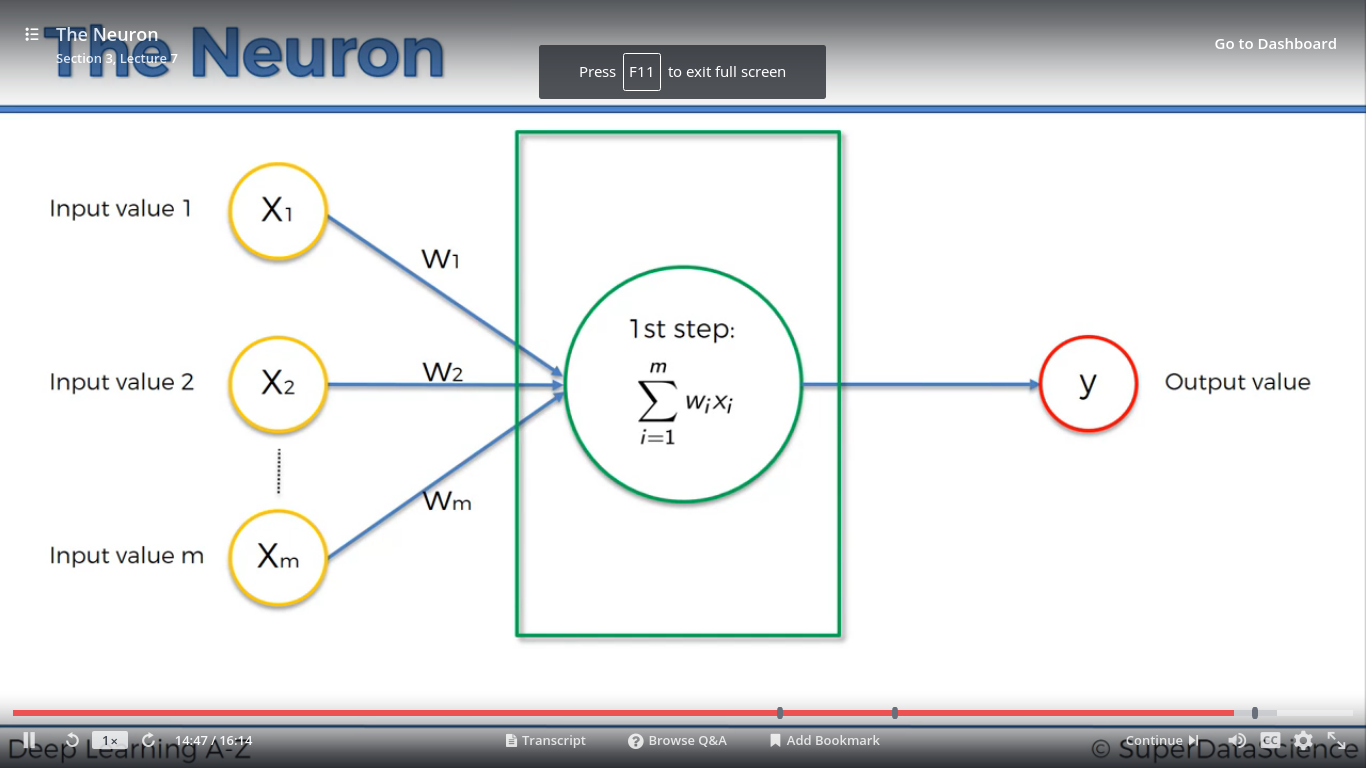
Bước 2: Giá trị đầu ra Y được tính thông qua hàm kích hoạt ( activation function)
Y=f(x)
Hàm f(x) này được quy định từ trước, không thay đổi. Mỗi loại nơ-ron khác nhau có hàm f(x) khác nhau.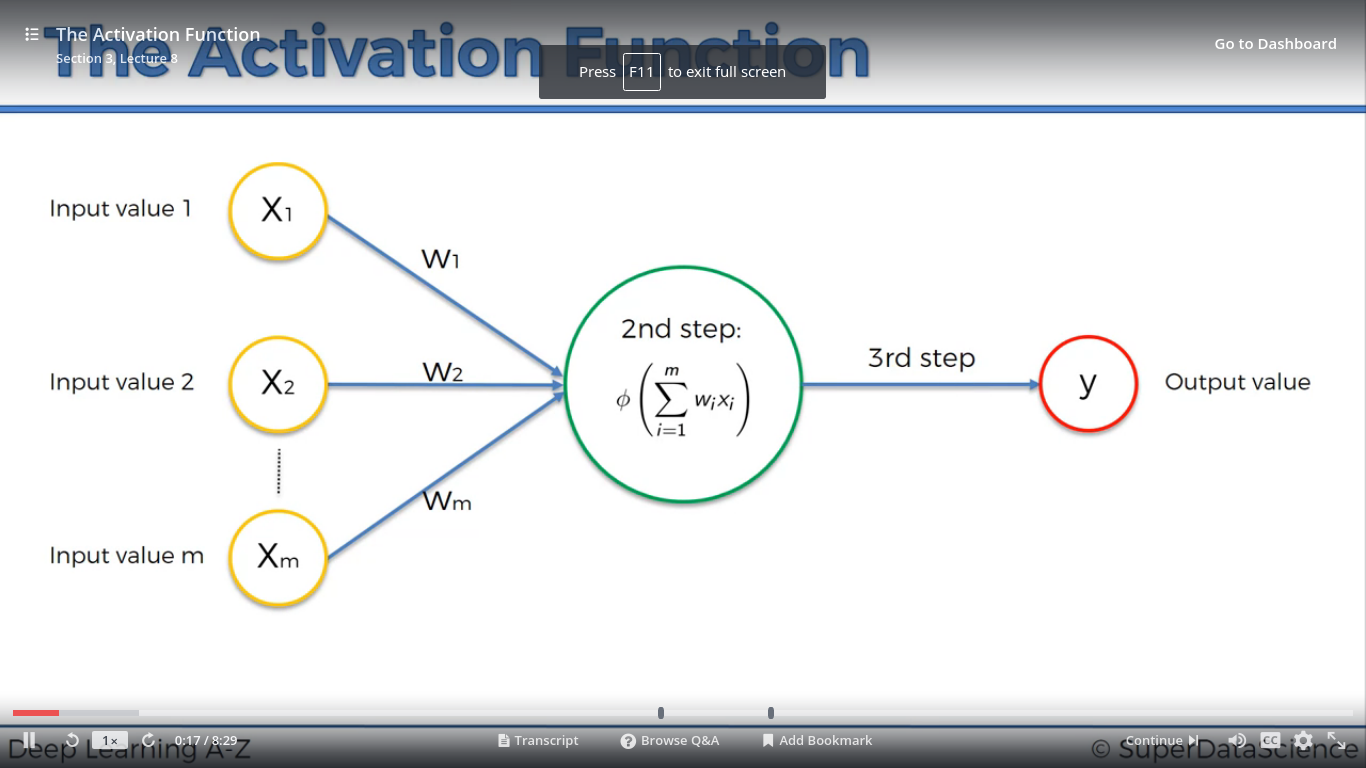
Bước 3: Truyền cho nơ-ron tiếp theo.
Các hàm kích hoạt
Hàm ngưỡng
Y=1 khi X>=0
Y=0 khi X<0
Không được sử dụng trong thực tế.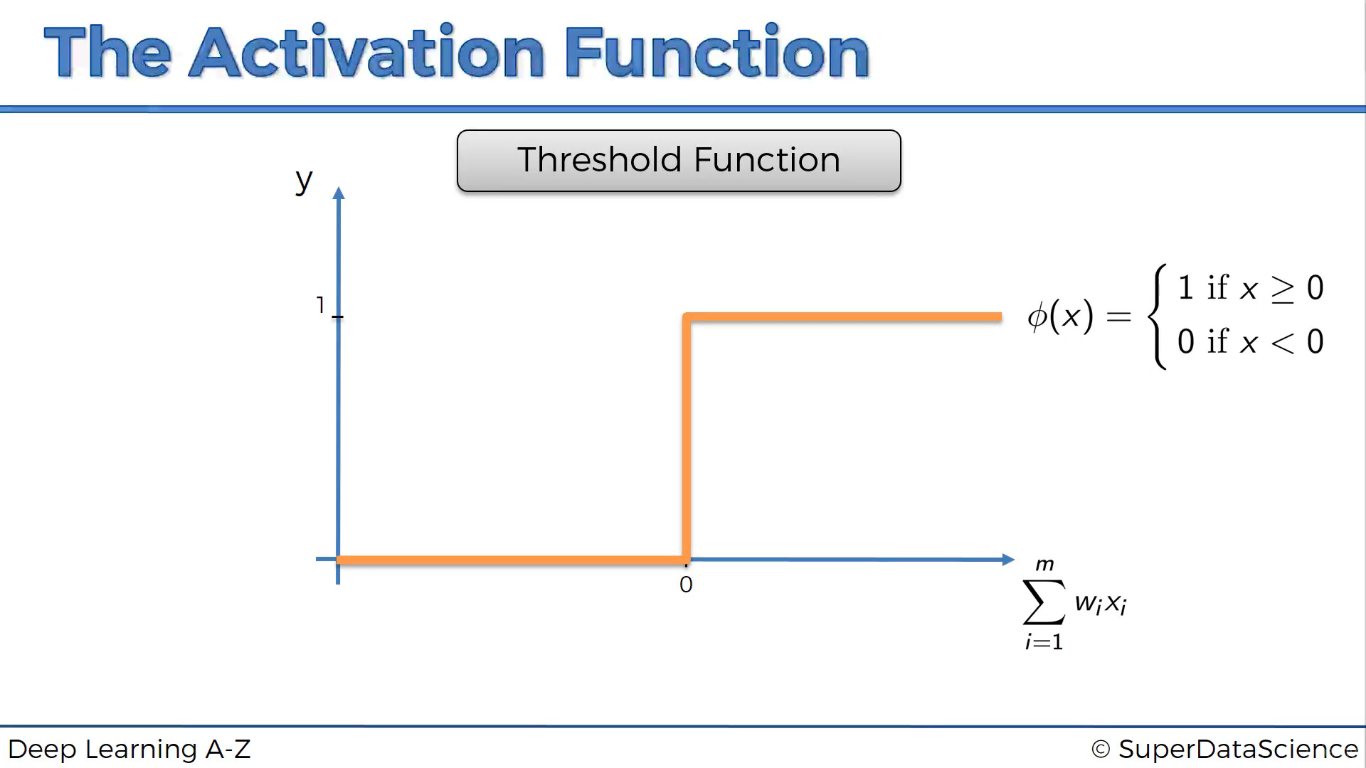
Hàm sigmoid
Mấy hàm này nhìn hình là hiểu mà. Cần gì phải giải thích :p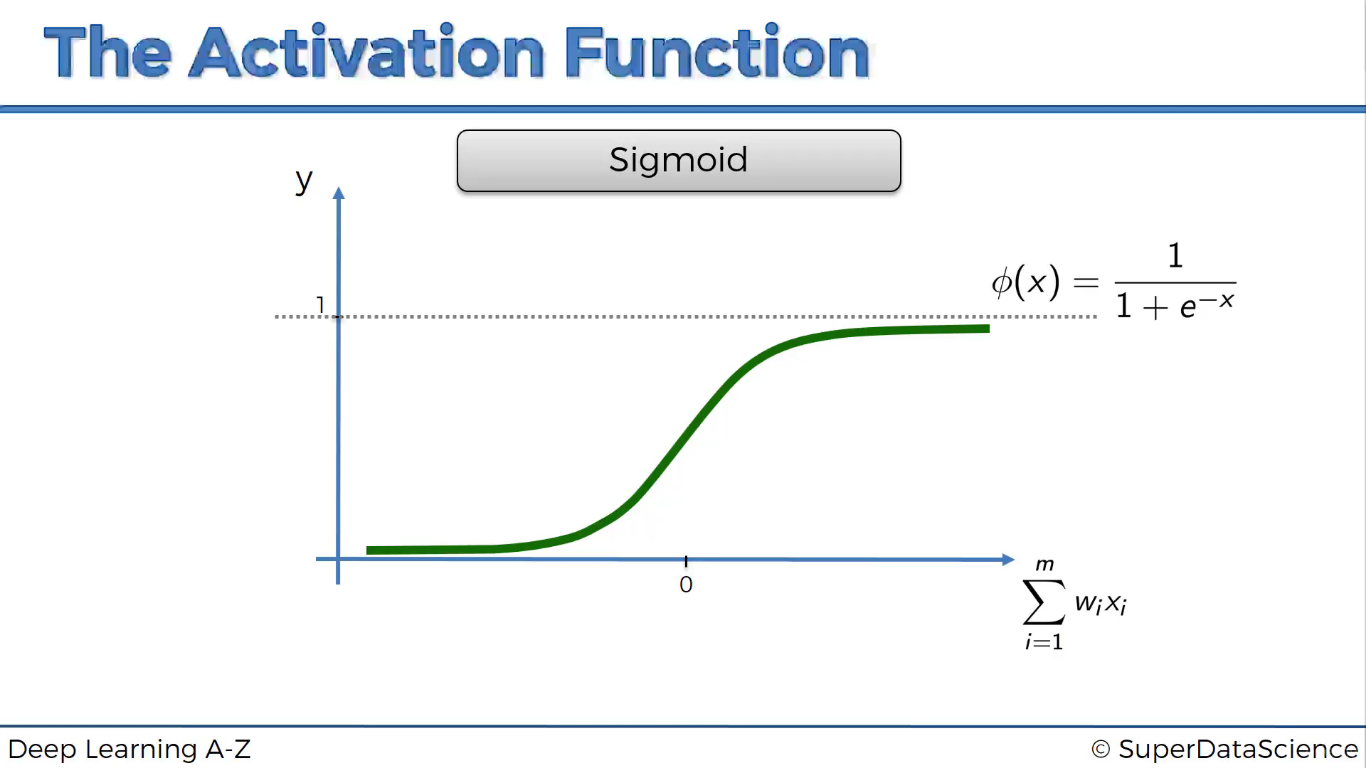
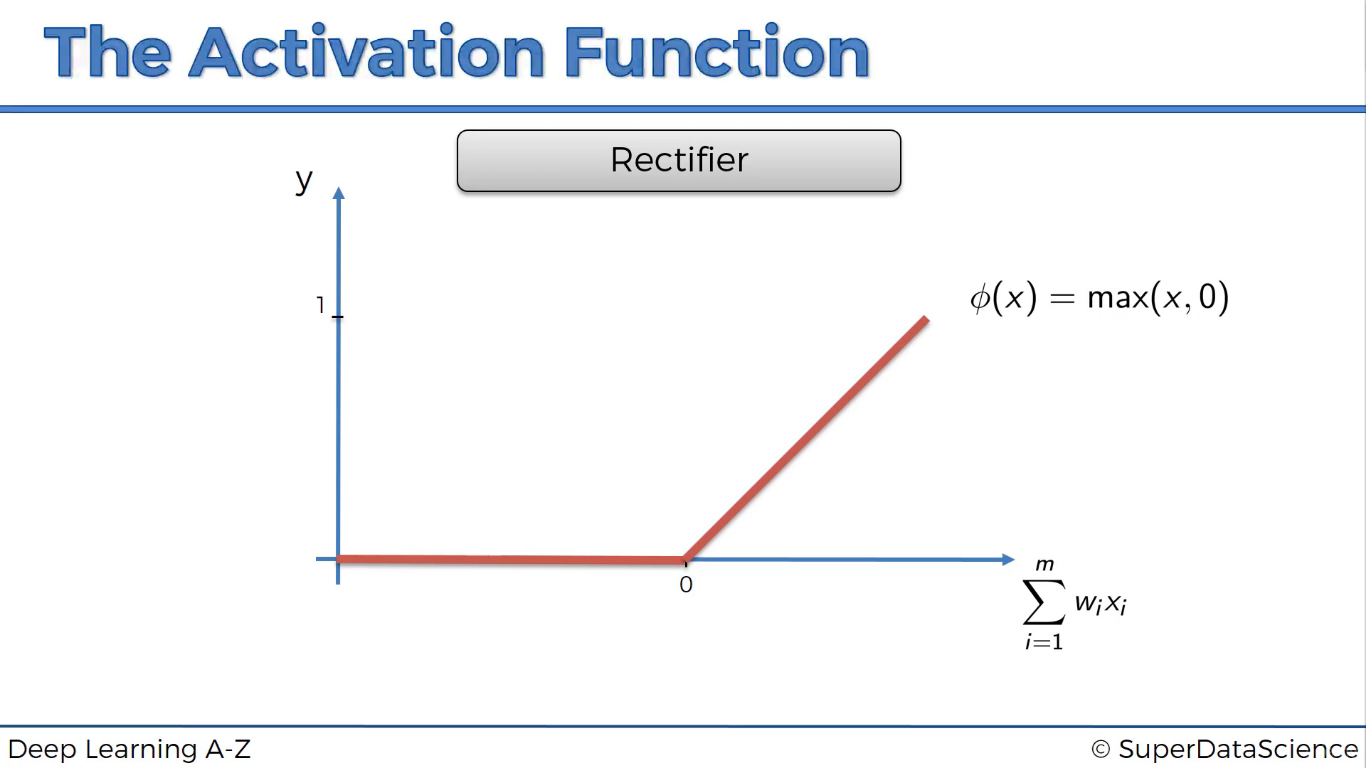
Hàm Rectifier (ReLU)
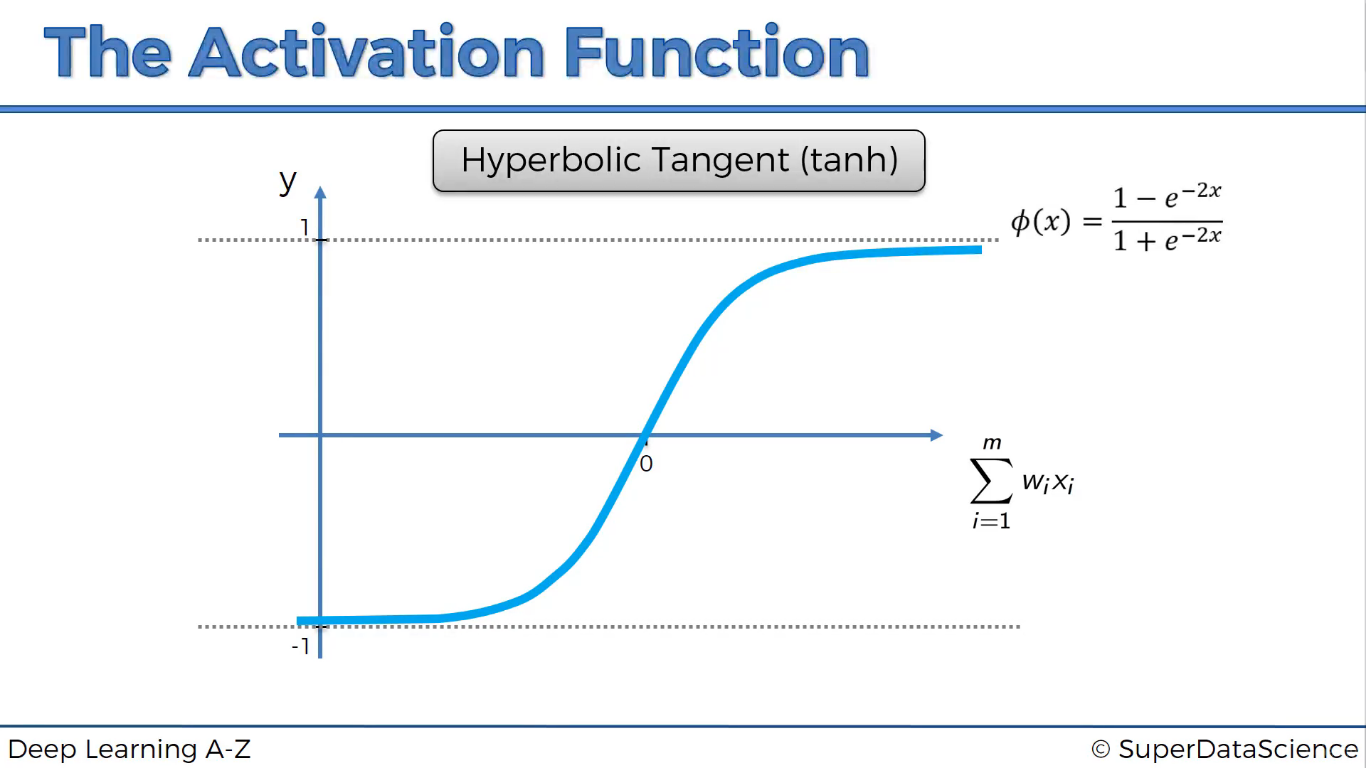
Hàm tank
Mạng nơ-ron hoạt động như thế nào
Do các trọng số có giá trị khác nhau nên với mỗi nơ-ron, các biến sẽ có độ quan trọng khác nhau.
Với chủ đề dự đoán giá nhà chẳng hạn, nơ-ron đầu tiên chỉ coi diện tích và khoảng cách là quan trọng.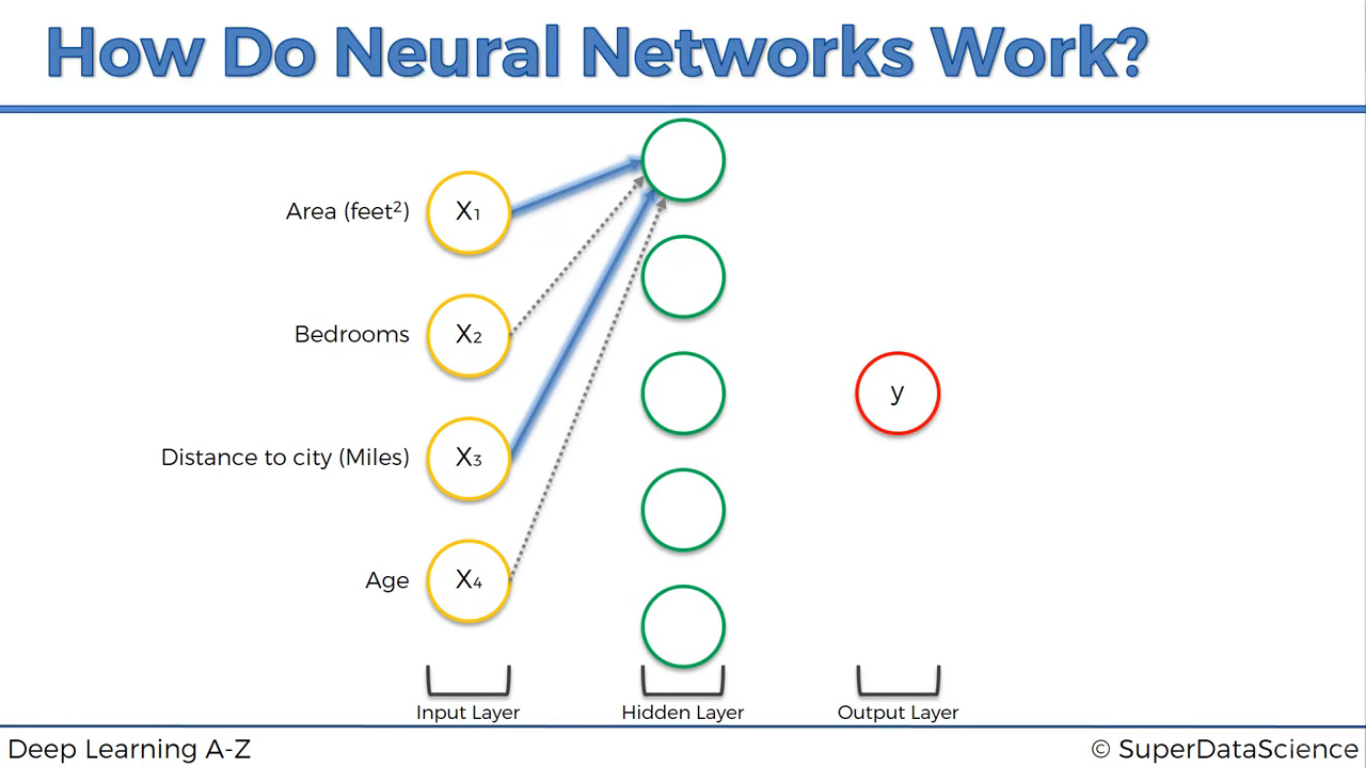
Nơ-ron thứ 2 chỉ có phòng ngủ và khoảng cách là quan trọng.
…
Tập hợp tất cả lại sẽ đc mạng nơ-ron. Mạng này có thể dự đoán giá nhà theo các giá trị đầu vào.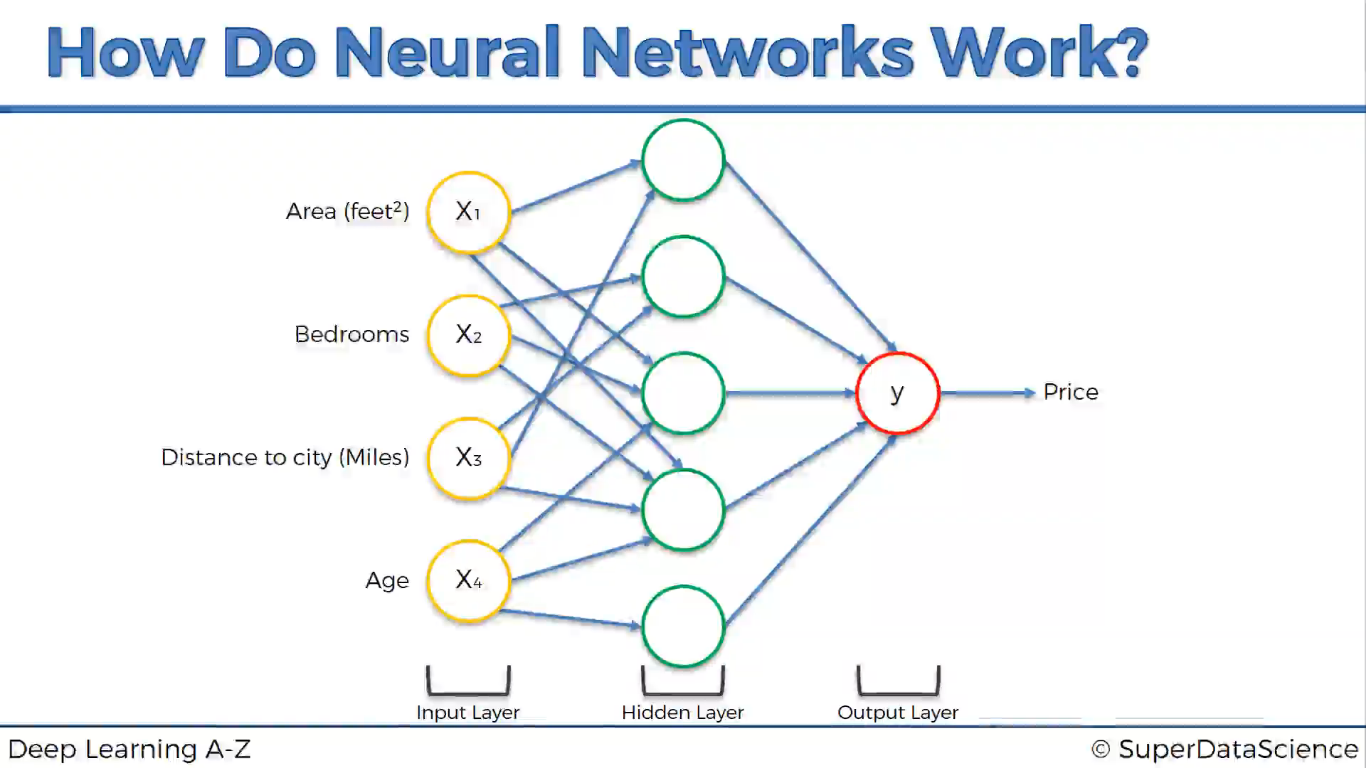
Mạng nơ-ron học như thế nào
Người ta bịa ra cái hàm mất mát (cost function), đo tỉ lệ dự đoán sai của mạng nơ-ron.
Khi dự đoán sai, giá trị dự đoán Y’ khác Y thật thì hàm cost cho giá trị lớn. Các trọng số W được điều chỉnh để giá trị hàm mất mát (C ) bằng không.
Hàm mất mát cụ thể là hàm nào thì chưa biết.
Quá trình điều chỉnh lặp lại cho đến khi giá trị mất mát =0. Tức là đoán chính xác 100%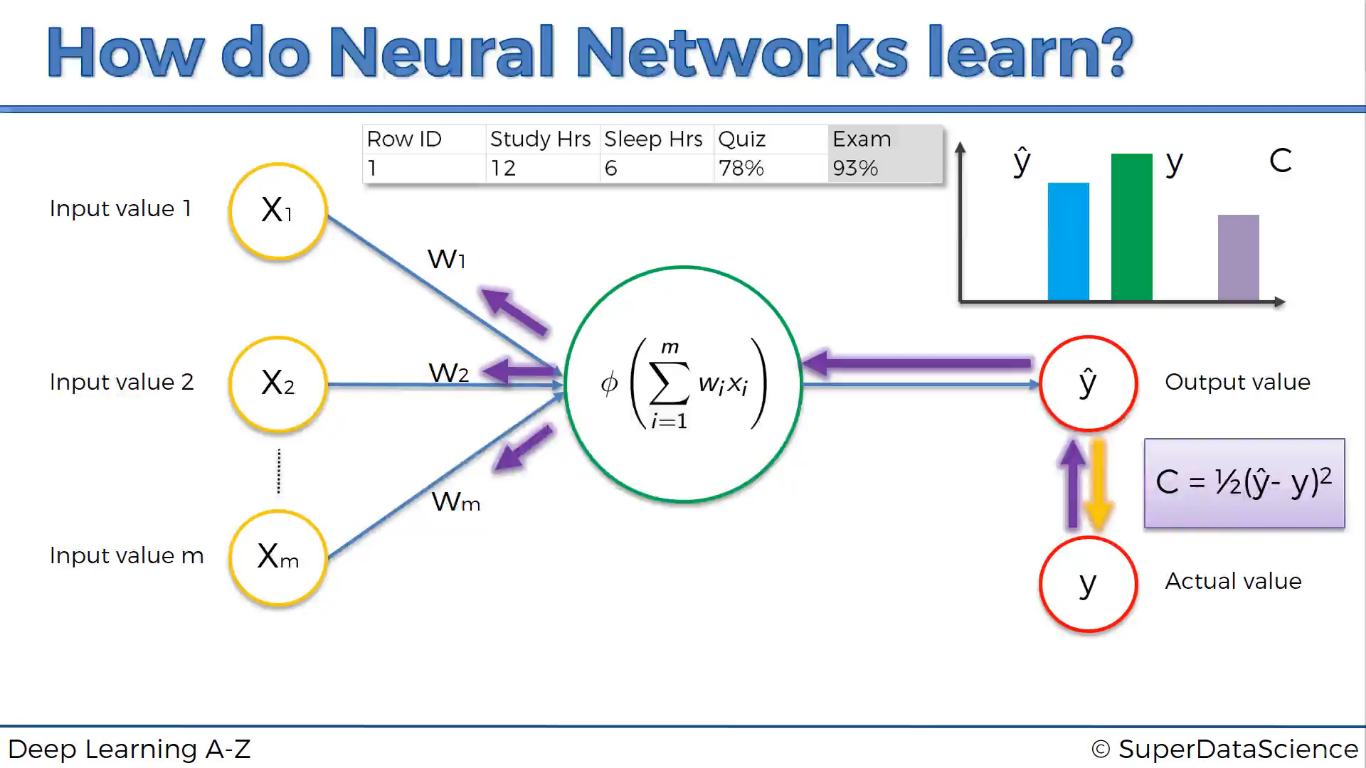
Gradient Descent
Để tìm giá trị nhỏ nhất của hàm mất mát C, người ta dùng phương pháp Gradient Descent.
Từ này trong tiếng việt có nghĩa là Giảm độ dốc. Có nghĩa là tìm về vị trí cực tiểu có độ dốc =0.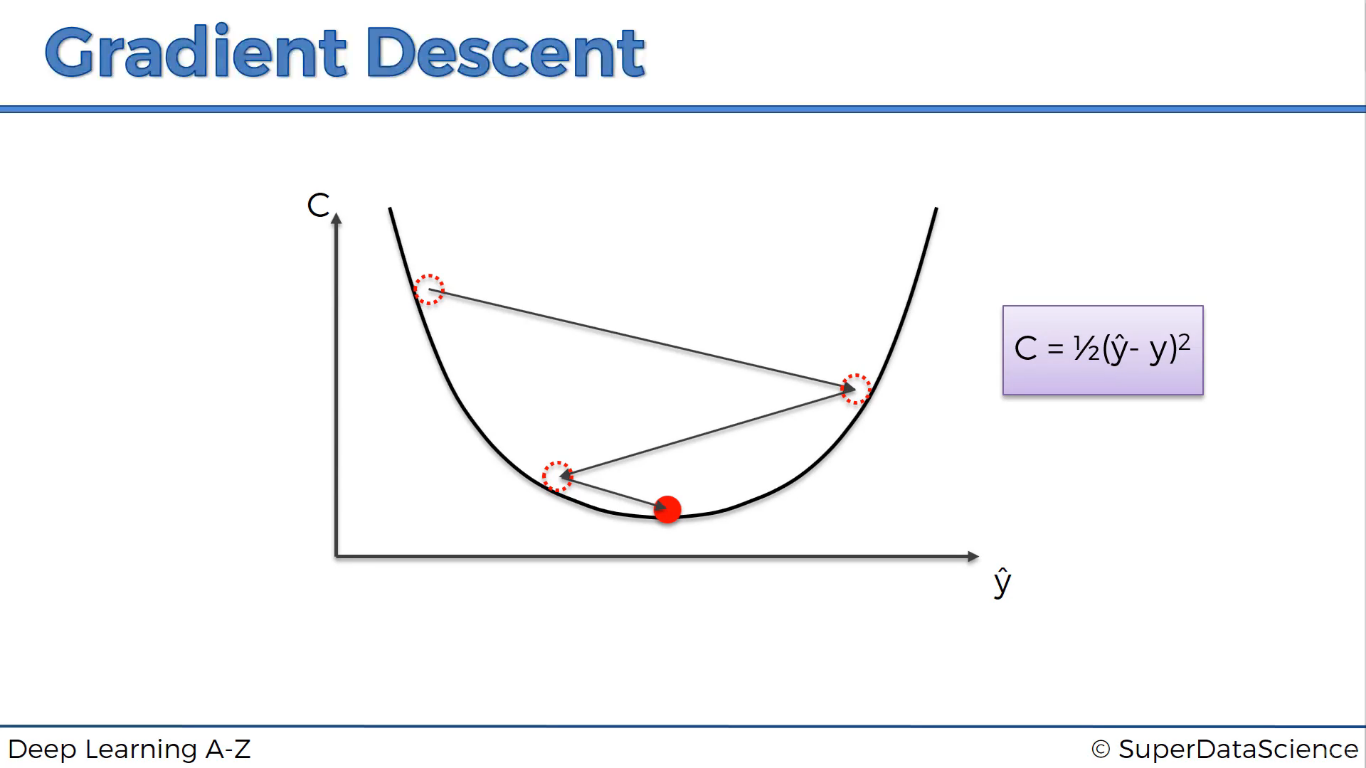
Làm cách nào để tìm được cực tiểu. Dùng đạo hàm. Đù, nhiều toán quá. Bỏ qua!!
Nội dung chi tiết xem tại:
https://machinelearningcoban.com/2017/01/12/gradientdescent/#-gioi-thieu
https://machinelearningcoban.com/2017/01/16/gradientdescent2/
https://dominhhai.github.io/vi/2017/12/ml-gd/
http://ruder.io/optimizing-gradient-descent/index.html
Nhiều cực tiểu thì thế nào???
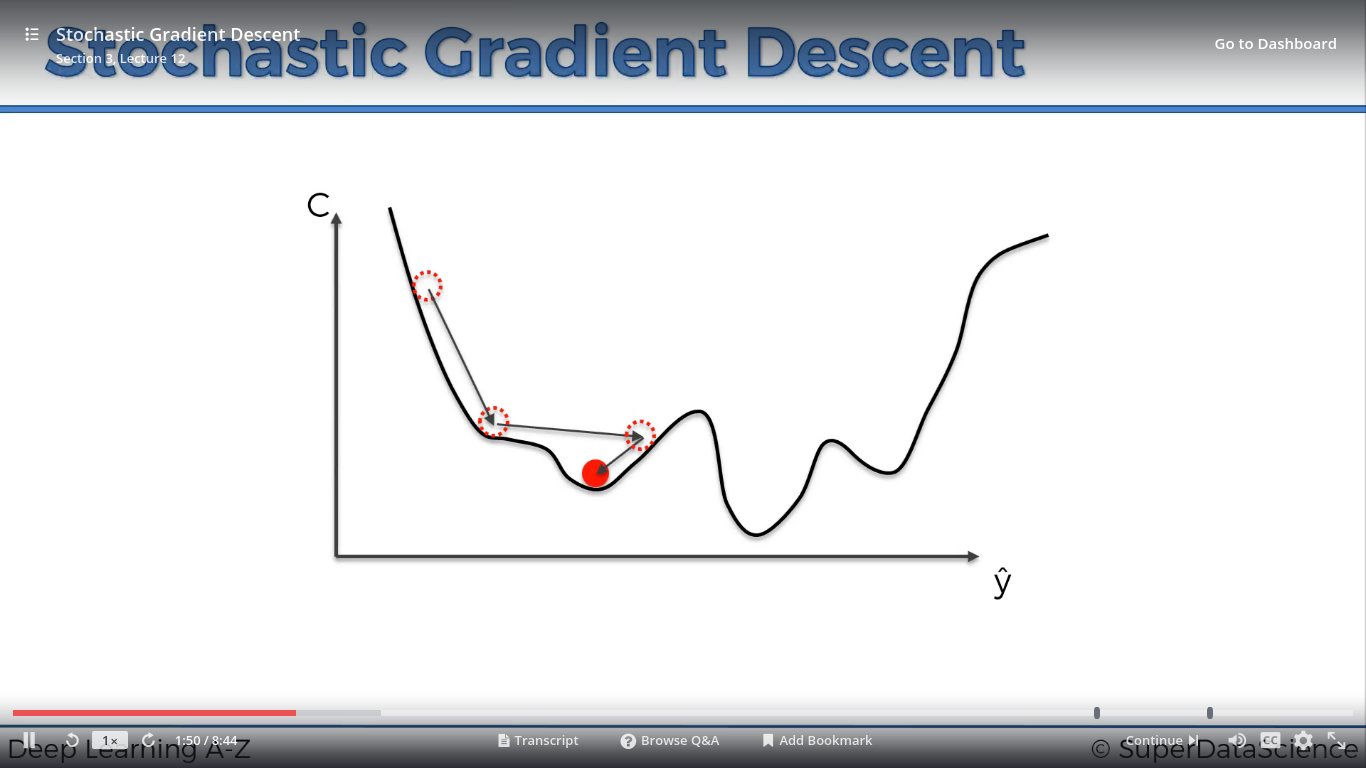
Biến thể của Gradient Descent
- Batch Gradient Descent
Hàm mất mát đc tính trên cả bộ dữ liệu, sau đó điều chỉnh trọng số để tìm cực tiểu. - Stochastic Gradient Descent
Hàm mất mát tính trên từng dữ liệu và điều chỉnh trọng số. Cách này tránh đc cực tiểu địa phương, tìm được cực tiểu toàn cục.
Lan truyền ngược (backpropagation)
Diều chỉnh trọng số theo chiều ngược từ các lớp gần output đến các lớp input.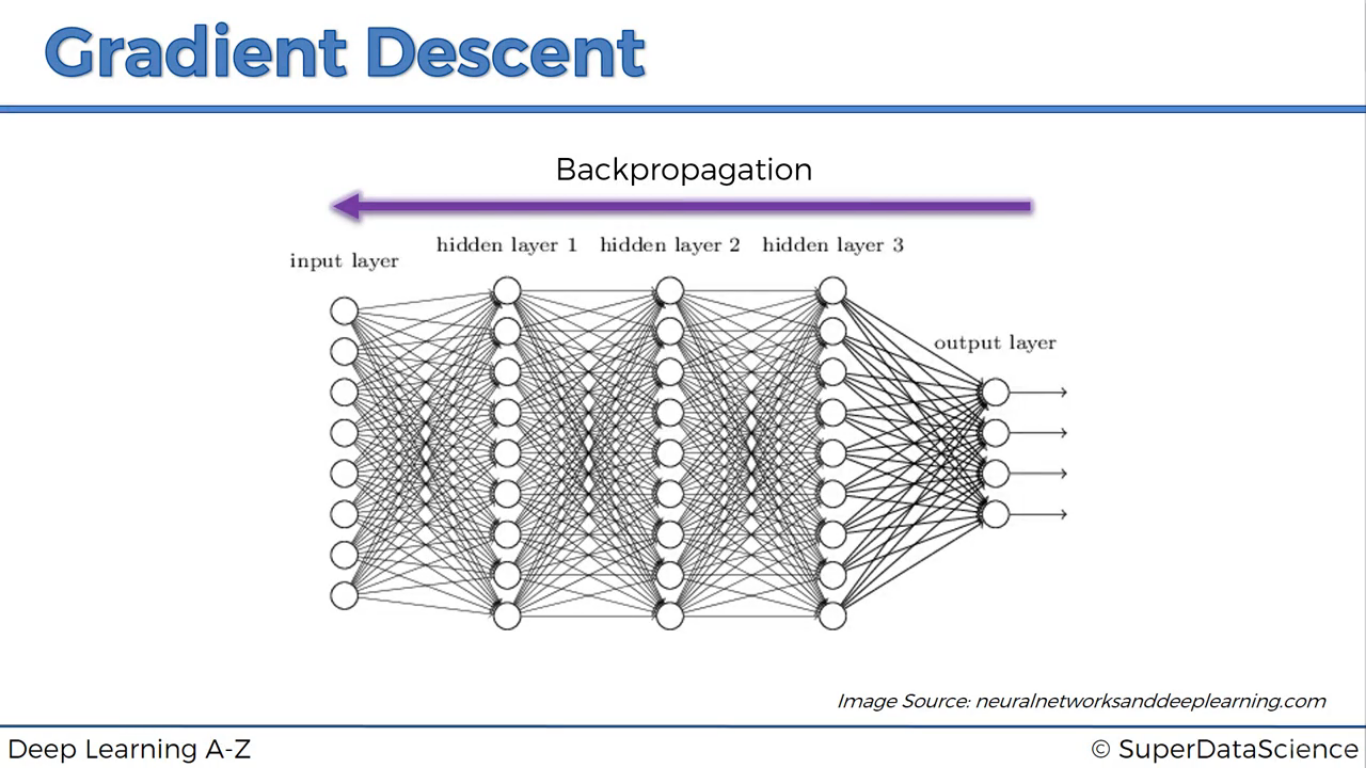
Cụ thể xem tại:
https://machinelearningcoban.com/2017/02/24/mlp/#-backpropagation