
Học deep learning phần 1
Từ hôm nay, mình bắt đầu học về deep learning theo một giáo trình cụ thể.
Hồi học đại học, mình có học về machine learning. Những khái niệm cơ bản như học có giám sát, học không giám sát, phân lớp, … cũng đã biết qua. Sau 2 năm ra trường, chắc quên khá nhiều rồi. Cách mạng 4.0 sẽ là cách mạng của IoT, AI, rô-bốt, xe tự lái, công nghệ sinh học, nano. Giờ 25 tuổi, có nghĩa là cả đời sẽ chứng kiến cuộc cách mạng này và thành quả của nó. Không nhảy vào thì chỉ có con đường tụt hậu. Vì vậy, mình đăng kí khóa học Deeplearning A-Z của Udemy.
Trong quá trình học, mình sẽ ghi chép các nội dung chính, quan trọng ở trên blog này. Vừa để ghi nhớ, vừa để dễ tra cứu sau này.
Bác nào thấy có sai sót gì thì thông báo cho mình ngay để mình update lại kiến thức nhé. Sau ngay ban đầu mà lại ở kiến thức cơ bản thì nguy hiểm lắm.
Hôm nay học bài 1: Deep learning là gì. Cài python, lấy data của môn học, các tài liệu khác.
Deep learning là gì.
Deep learning là 1 mảng nhỏ hơn trong machine learning. Trong machine learning có mạng nơ-ron và nhiều loại khác nữa. Mạng nơ-ron gồm 3 lớp: lớp đầu vào, lớp ẩn, lớp đầu ra. Mạng nơ-ron có nhiều lớp ẩn gọi là Deep learning.
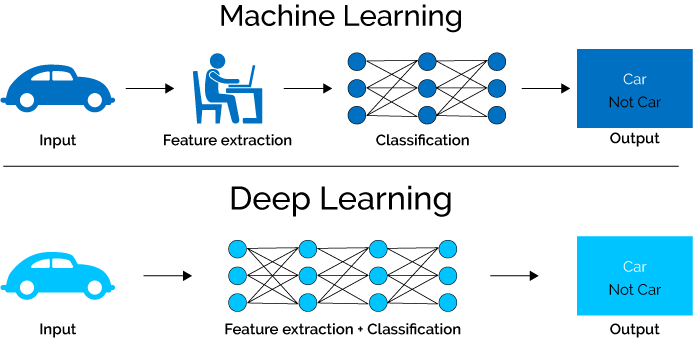
Hình ảnh trên lấy từ nguồn này.
Cài python
Dùng python 3.6, tải từ trang https://www.anaconda.com/download/#linux
Bản phân phối python này có sắn IDE, thư viện các kiểu.
Dữ liệu dùng khi học
Tải từ trang này
https://www.superdatascience.com/deep-learning/
Xong bài 1. Easy!
Update 2018/08/18: Nguồn gốc Deep learning.
<Đọc đếch hiểu gì, toàn khái niệm mới. Sẽ tìm hiểu sau. >
Năm 2006, Hinton giới thiệu ý tưởng của tiền huấn luyện không giám sát (unsupervised pretraining) thông qua deep belief nets (DBN). DBN có thể được xem như sự xếp chồng các unsupervised networks đơn giản như restricted Boltzman machine hay autoencoders.
Lấy ví dụ với autoencoder. Mỗi autoencoder là một neural net với một hidden layer. Số hidden unit ít hơn số input unit, và số output unit bằng với số input unit. Network này đơn giản được huấn luyện để kết quả ở output layer giống với kết quả ở input layer (và vì vậy được gọi là autoencoder). Quá trình dữ liệu đi từ input layer tới hidden layer có thể coi là mã hoá, quá trình dữ liệu đi từ hidden layer ra output layer có thể được coi là giải mã. Khi output giống với input, ta có thể thấy rằng hidden layer với ít unit hơn có để mã hoá input khá thành công, và có thể được coi mang những tính chất của input. Nếu ta bỏ output layer, cố định (freeze) kết nối giữa input và hidden layer, coi đầu ra của hidden layer là một input mới, sau đó huấn luyện một autoencoder khác, ta được thêm một hidden layer nữa. Quá trình này tiếp tục kéo dài ta sẽ được một network đủ sâu mà output của network lớn này (chính là hidden layer của autoencoder cuối cùng) mang thông tin của input ban đầu. Sau đó ta có thể thêm các layer khác tuỳ thuộc vào bài toán (chẳng hạn thêm softmax layer ở cuối cho bài toán classification). Cả network được huấn luyện thêm một vài epoch nữa. Quá trình này được gọi là tinh chỉnh (fine tuining).
Tại sao quá trình huấn luyện như trên mang lại nhiều lợi ích?
Một trong những hạn chế đã đề cập của MLP là vấn đề vanishing gradient. Những ma trận trọng số ứng với các layer đầu của network rất khó được huấn luyện vì đạo hàm của hàm mất mát theo các ma trận này nhỏ. Với ý tưởng của DBN, các ma trận trọng số ở những hidden layer đầu tiên được tiền huấn luyện (pretrained). Các trọng số được tiền huấn luyện này có thể coi là giá trị khởi tạo tốt cho các hidden layer phía đầu. Việc này giúp phần nào tránh được sự phiền hà của vanishing gradient.
Kể từ đây, neural networks với nhiều hidden layer được đổi tên thành deep learning.
Lịch sử của Deep learning có thể đọc chi tiết hơn tại đây.